Dataverse Solutions explained
With the rising number of citizen developers, I thought it might be time to write a blog post explaining Dataverse Solutions. When developing/configuring within Dataverse one question comes up pretty soon
How do I get my changes from one environment to another
That’s where Solutions come into the picture. Let’s see what they are good for and what the dos and don’ts are.
Basics
Let’s talk a bit about the basics of a Solution
What is it?
A Solution is basically just a container that bundles a list of components. When a component is added to a solution a pointer to the component will be created. This means that when a component that is included in several solutions is changed it is changed in all of them.
At least when all the solutions are unmanaged, but more about that later.
The following picture tries to explain this. When you have two solutions (Solution A and Solution B), both contain the contact table with a certain column. When this columns requirement level will be changed to “Business Required” this configuration is changed in both solutions.
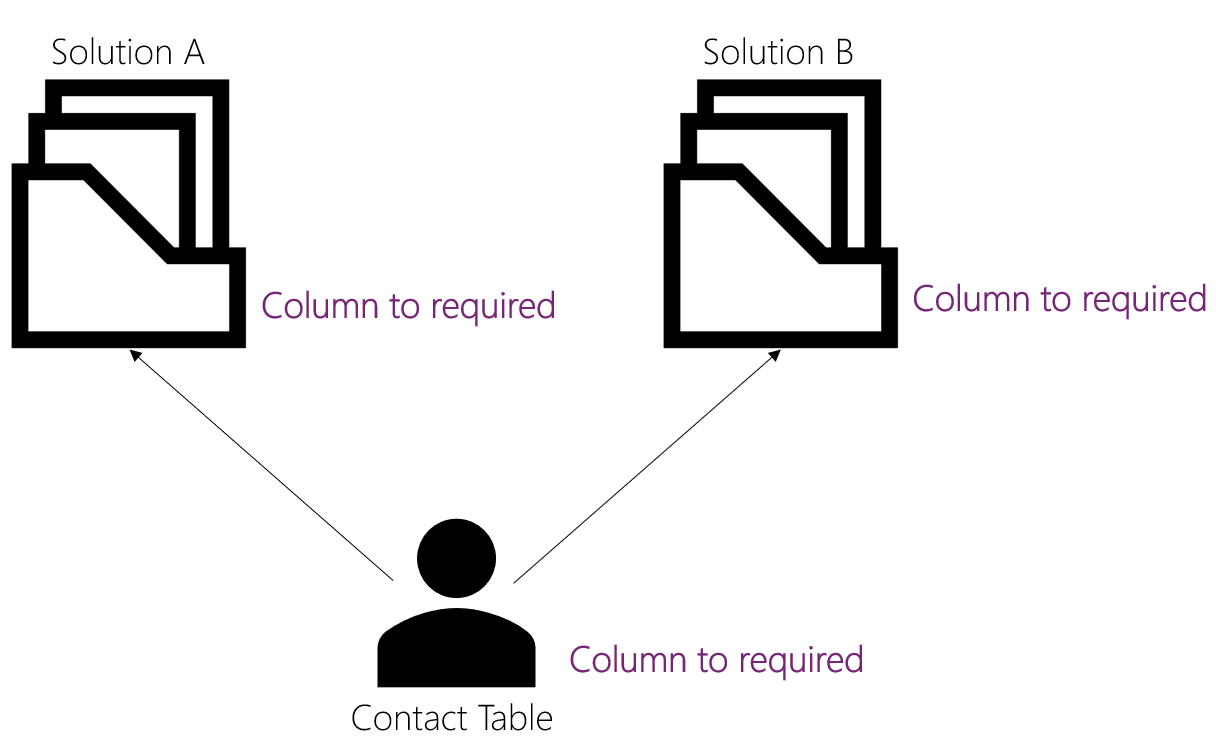
Use-case
Once you have all your components within your solution you can use it to move them to another downstream environment. This is actually the main purpose of a solution.
Details
Now that we have talked about the basics of solutions we will go a bit more into detail.
Customization vs. Data
I mentioned that you can add components to a solution to be able to move it to another environment.
It’s important to mention/know that not all parts of Dataverse are “solution aware”, which means not all parts could be components within a solution.
Basically “only” customizations (like tables, columns, Power Automate flows and many more) can be added to a Solution, whereas Data (rows of data within a table) can’t.
There are exceptions to that rule. Microsoft made data of some important Out of the Box (OOB) tables solution aware. Those are for example Environment Variables, Settings, Email Templates or Connection Roles.
Unmanaged vs. Managed
When it comes to Solutions there is a long-lasting debate about Unmanaged vs. Managed. Let me explain to you what the difference is.
A new solution will always be created as unmanaged. The difference comes when one exports the solution, here it could be chosen from either unmanaged or managed (default). But what does it mean?
Unmanaged
If a solution is installed as unmanaged in an environment you will be able to:
- Add compontents
- Remove components from the solution
- Delete component from the environment
- Export the solution as unmanaged
- Export the solution as managed
- When deleted only the container will be deleted, where as the components remain in the environment
You could say an unmanaged solution is a loose container of components.
Managed
If a solution is installed as managed in an environment you will not be able to change the solution (add or remove components). When a managed solution is deleted/uninstalled all the included components will be deleted as well.
There is an exception to that as well. If the component is included in another managed solution it will remain in the system. This makes it easier to change the solution structure.
You could say a managed solution is a tight container of components.
Why is this a good thing?
This question inevitably comes to mind.
Managed solutions come from managing Independent Solution Vendor (ISV) solutions. The idea was to have the possibility to protect an ISVs property and still be able to ship functionality to the customer.
Even though that’s the origin it is very helpful in every project. Some examples are:
Different Dev Teams
When you have different development teams it might be handy to “protect” the solutions of those teams. Maybe one team develops a base solution on top of the other teams building their own. In that case, it would be nice then only the development team of the base solution can change stuff in it.
Citizen Developers
Often the customer themself would like to make changes. Maybe as easy as adding views and Dashboards or even more complex stuff as creating custom columns or tables. In that case, the implementation partner might want to protect their own solution to protect themself from bugs created by the customer themselves.
In addition to the stuff I mentioned above, there is the possibility of Upgrades when one is using managed solutions. Which in my opinion is the biggest advantage. Another advantage could be layering. I will explain those parts in detail a bit later in this blog post.
Conclusion
Microsoft’s recommendation and way to go is definitely that every environment which isn’t Development should be handled with managed solutions. Which also is my recommendation. There has been a lot of investment into ALM in general but Managed solutions in particular in the last months/years. They do work much better than they did back in the days of older versions (for example Dynamics 2013).
Update vs. Upgrade
When it comes to installing a solution you will have two different possibilities.
- Update
- Upgrade
Let’s explore those two a bit more.
Update
An update is a way that is there since we have solutions. When a solution is installed as an update new components will be installed and existing components will be updated. If a component was in the solution earlier but isn’t any longer it will remain within the solution in the target environment.
Upgrade
Upgrade is around for some time now as well, but it was added as an option later and wasn’t there from day 1.
If a solution is installed as an Upgrade the system will first install the new version as a holding solution (called <SolutionName>_Upgrade in the Solution list) and then the upgrade will be applied. This could either be done in two steps (manual apply) or in one.
Within a pipeline, you will always need 2 steps.
Installing an upgrade will also install new components and update existing ones. The important part is that an upgrade will delete stuff from the environment which isn’t included in the solution any longer.
If you, for example, have a column on a table that you don’t need any longer you can just delete it from dev and the next upgrade will also erase it from the downstream environments.
This allows us to hold our test and production environment clean and we will not collect unused/unneeded waste over time.
Be aware that the solution version you try to install needs to be higher than the current in the environment installed solution to be able to perform an upgrade install.
When an upgrade is installed the changes will be effective even though it’s not applied yet.
Use-case of manual upgrade
As mentioned there is the possibility for a manual upgrade.
This is particularly helpful if you have some migration job to do.
Let’s assume you have created a column and it is in production use already. After a while you discover that something is wrong with it, for example, the schema name doesn’t follow your naming convention (which you hopefully have), the data type isn’t correct or anything else.
What you could do is create a new column, delete the old one, install it as an upgrade and before you apply the upgrade (which would delete the old column) you migrate your data over.
With that you only need one deployment and still are able to keep the data.
Layering
If you have different solutions installed the system has to decide which changes do “win”. Let’s say you have several solutions changing the max size of a text field. Which of those is the max size you will get?
That’s where Layering comes into the picture.
There is one unmanaged layer. All unmanaged solutions and ad-hoc changes are in this layer. Which makes it hard to distinguish the “winner” when using unmanaged solutions all the way.
Every managed solution creates its own layer where the latest installed solution is above the previously installed one.
If two managed solutions do have clashing configurations there are two different approaches to fix it:
- Last installed wins
- Merge (only used by model-driven apps, forms, and site map components)
Even within a managed solution, there are layers. A patch for example “wins” over the base solution.
Patching vs. Cloning
Usually, you just set a higher solution version when you export the solution. This was previously done by cloning the solution (where the first 2 parts of the solution version could be changed). Today you don’t need this step to change the version.
There is however another part that is interesting even today. One could patch a solution. When a solution is “patched” a new empty solution is created. The name will be <SolutionName>_Patch<number>. Here you could add just the components you’d like to deploy. This makes a quick deployment possible since the install doesn’t need to process all the components.
It does come with some cons, though.
- The version of the base solution the patch was created from needs to be the exact same as you have in your target environment
- Because of the mentioned cons and the different names patches are basically not to handle in an automated process
They are very useful when it comes to hotfixes. Here some consideration in regards to environments is needed. I might create a different post on that later.
Tips
So let’s come to the tips I have when it comes to Solutions. I am sure I have forgotten a lot of them. Feel free to contact me if you have others.
Split Solutions
What usually is needed is to split solutions. For example, having flows in a separate solution since the ALM story of them isn’t quite there yet (even though we are getting closer). Another thing you usually need to split out is custom connectors. Those need to be installed before the using Flows get installed.
Several Solutions same component
Make sure that the same component is only included in one solution. If you have it in several solutions you might create dependencies between your solution which you can’t resolve later.
Include all
When you add existing tables to your solution don’t include them with all the subcomponents (it’s a checkbox in the add wizard). This might otherwise create problems with dependencies later.
For example, if an ISV adds some field to an OOB table and you include this table to your solution with all subcomponents you might get problems installing a new version of the ISV solution where the mentioned field will be deleted.
Be aware that the system adds a table with all subcomponents whenever you add a lookup to a table. The parent table gets added when it is not present already. Make sure to add the parent table without all subcomponents before you add the lookup to it.
Conclusion
As you can see solutions are a big topic. They can be complicated to understand as well.
I hope this blog post has explained Dataverse Solutions and it helps someone to understand them better. Feel free to contact me if you have any more questions or give me feedback. For example, if I forgot something.
You can also subscribe and get new blog posts emailed to you directly.
About The Author
Benedikt
Power Platform Consultant @ CRM Konsulterna
Great article, small typo here: “deleted onöy the container” 🙂
Thanks for the feedback. It’s fixed now.
I’m sorry I don’t understand. Are environments part of a solution, or is a solution part of an environment?
A Solution is part of an Environment.
One uses Solutions to move components/changes from one Environment to another. For example from Development to Test or Production.
Very well explained, thanks for sharing. Another tips that I usually tell to citizen developers is to
* Create a publisher for your org to use consistently across your environments, if you have multiple business lines/streams consider creating one publisher per stream especially if you have a multiple people working in different streams.
Thanks for the feedback.
Out of curiosity: Why do you see the need for having different publishers for different streams?
Great description, thank you! Small typo her (imho) : “When you ad existing tables to your solution”
Benedikt,
Previously, I’ve used multiple publishers to differentiate the use cases for a field. If a field is used by Marketing, vs Customer Service, vs. Sales for instance. Or if there’s a field required by an integration. Having multiple publishers can help tell me who I need to talk to about a specific field’s use.
Thank you Benedikt, really useful article. Am a long term professional devekoper just picking up PowerApps now. Answered a lot of my questions.
Hi Benedikt,
I wonder about two subjects when it comes to solutions.
1. I shared the APP with Users. What will happen when I upgrade/update solution, will the link to APP still be active or it will change?
2. My users have problems when running Flows from button in APP. Are there any limitations to using flows in managed solution for basic users that you are aware of?
Thanks!
Kornel
Hej Kornel,
thanks for your comment.
1. The link should not change and the app should also be shared as before the upgrade/update
2. Do you mean they don’t see them listed in the “flow” button?
[…] Bergmann made a post Dataverse Solutions Explained. Follow his blog for more ALM related posts. He even wrote a book about ALM for Power Platform! […]